Adding robots.txt to your website
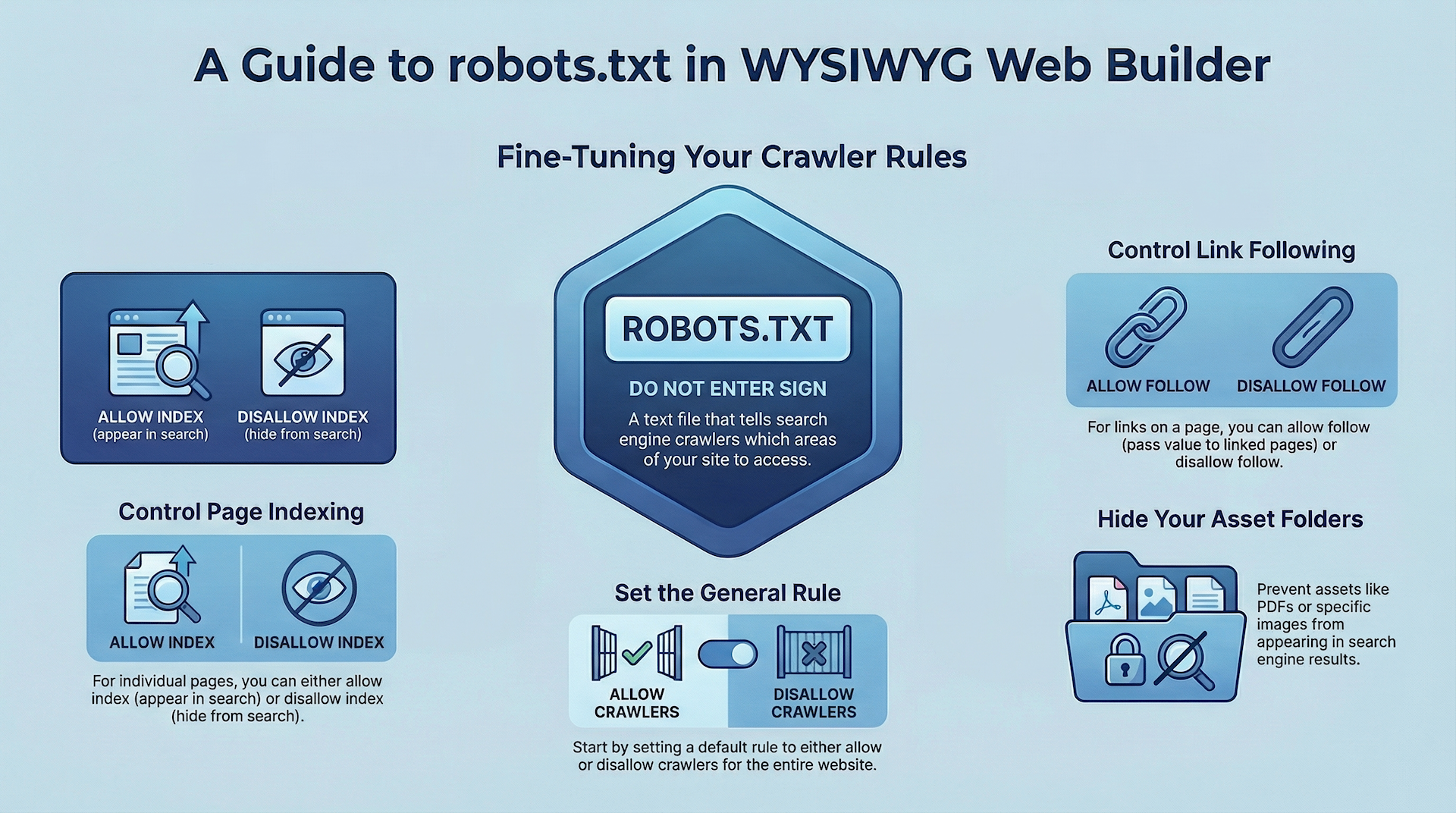
Robots.txt is a text file with instructions for search engine crawlers. It defines which areas of a website crawlers are allowed to search.
You can configure whether to allow / disallow the entire website or configure the rules for each folder individually.
You can configure whether to allow / disallow the entire website or configure the rules for each folder individually.
Generate robots.txt
Specifies whether to generate robots.txt file when the website is published. The file will be published in the root of the website.
For example: https://www.yourwebsite.com/robots.txt
Specifies whether to generate robots.txt file when the website is published. The file will be published in the root of the website.
For example: https://www.yourwebsite.com/robots.txt


General Rule
This sets the rule for the entire website. This can be overridden for each page and folder.
Allow all, allow robots to index all pages and folders on the web site .
Disallow, disallow robots from indexing all pages and folders on the web site.
This sets the rule for the entire website. This can be overridden for each page and folder.
Allow all, allow robots to index all pages and folders on the web site .
Disallow, disallow robots from indexing all pages and folders on the web site.

Pages and Folders
Under 'Pages and Folders' you can override rules for individual pages and folders.
First select the page in the site tree and then select one of the rules from the drop down list:
not set
The page will use the rule as configured in the 'General' section.
allow index
Tells a search engine to index a page.
disallow index
Tells a search engine not to index a page.
allow follow
Even if the page isn’t indexed, the crawler should follow all the links on a page and pass equity to the linked pages.
disallow follow
Tells a crawler not to follow any links on a page or pass along any link equity.
First select the page in the site tree and then select one of the rules from the drop down list:
not set
The page will use the rule as configured in the 'General' section.
allow index
Tells a search engine to index a page.
disallow index
Tells a search engine not to index a page.
allow follow
Even if the page isn’t indexed, the crawler should follow all the links on a page and pass equity to the linked pages.
disallow follow
Tells a crawler not to follow any links on a page or pass along any link equity.
Note
You can also set Robots index/follow options in the Page Properties. These are the same settings.
You can also set Robots index/follow options in the Page Properties. These are the same settings.

Asset Folders
In WYSIWYG Web Builder, assets (like images, pdf, videos, css, etc.) can be published to a different folder.
These folders can also be included / excluded for indexing. This can be useful if you do not want your documents (PDF) or images to be included in search results.
These folders can also be included / excluded for indexing. This can be useful if you do not want your documents (PDF) or images to be included in search results.

Asset folders can be configured in Tools -> Options -> Publish
